Datos, información y conocimiento
Introducción
Los sistemas basados en conocimiento se basan en los datos que se adquieren del entorno, para ello, estos datos se procesan para inferir conocimiento.
Gobierno del dato
Los datos son el centro de la actual producción de la industria en la que nos encontramos.
La eficiencia económica reside en obtener, transformar y compartir los datos de tal manera que aporten valor.
El gobierno del dato debe:
Crear un canal de comunicación para la correcta transmisión y compartición de los datos.
Proporcionar métodos para organizar, documentar y evaluar la calidad de los datos.
Asegurar privacidad, seguridad, integridad y control de acceso de los datos.
De esta manera, se logra mejorar la infraestructura, reduciendo gastos de operación y optimizando los procesos administrativos.
Jerarquía del conocimiento
La jerarquía del conocimiento suele representarse gráficamente por una pirámide, siendo los datos la base y el conocimiento la cima.
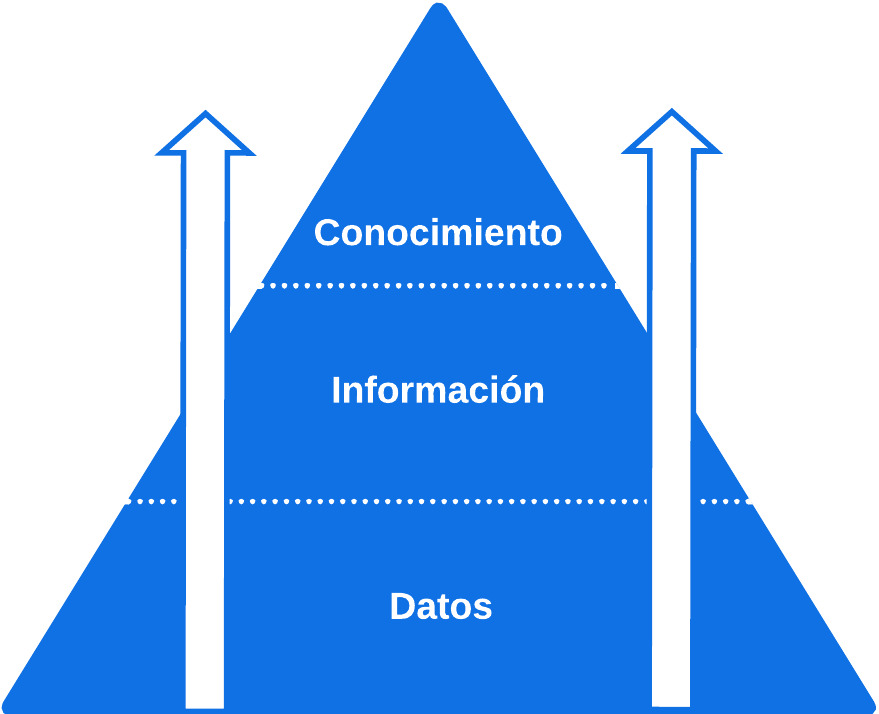
Datos
Un dato puede definirse como un hecho concreto y discreto acerca de un evento.
Discreto significa que, es la unidad mínima que puede comunicarse o almacenarse.
Aunque el dato tiene su significado propio, es difícil entender el significado de un dato sin conocer su contexto.
Ejemplos:
2010
443
DE
Tipos de datos
Estructurados
Un dato estructurado tiene un formato establecido (orden, estructura, características especiales...).
Sus fuentes de generación son dos:
Humano.
Generada por computador.
Los datos estructurados son de fácil manipulación e interpretación.
Ejemplos: Bases de datos relacionales, tablas, CSV...
No estructurados
Un dato no estructurado no tiene un formato específico y pueden estar almacenados en formatos variados como Word, PDF, imágenes, páginas web o correos electrónicos.
Sus fuentes de generación son dos:
Humano: encuestas, datos de redes sociales, correos...
Generada por computador: videos, audios, fotografías...
Los datos no estructurados suelen tener mayor valor informacional, pero su manipulación e interpretación resulta más compleja.
Semiestructurados
Los datos semiestructurados resultan de la combinación de los datos estructurados y no estructurados.
Ejemplos: Una oferta de empleo, porque puede contener:
Datos estructurados: salario, jornada laboral, años de experiencia...
Datos no estructurados: imágenes, texto libre...
Oscuros
Los datos oscuros, son los datos que se utilizan con propósitos diferentes para los que originalmente se obtuvieron.
Abiertos
Los datos abiertos, son datos de acceso y disponibilidad libre, sin restricción o limitación de ningún tipo, por lo que pueden ser usados o distribuidos, las veces que sean necesarias, por cualquier persona que lo desee.
Los datos abiertos deben poseer cuatro características:
Disponibilidad y fácil acceso sin coste agregado.
Reutilizable y redistribuible, pudiendo ser fusionados con otras fuentes.
Participación social: cualquiera puede acceder a ellos.
Sostenibilidad: deben mantenerse en el tiempo (sin limite temporal).
Los datos abiertos se centran en una gobernanza bajo principios éticos.
Metadatos
Los metadatos son datos que se usan para describir otros datos.
Clasificación:
Descriptivos: describen recursos de información.
Pueden incluir elementos como: nombre, autor, resumen, palabras clave...
Estructurales: facilitan la navegación por el recurso en formato electrónico.
Ejemplo: Tabla de contenido, índice de figuras...
Administrativos: facilitan el proceso de colecciones físicas o electrónicas.
Ejemplo: Formatos de archivos y otros datos de aspectos técnicos.
Los metadatos:
Facilitan la interoperabilidad de recursos.
Permiten descubrir información.
Mejoran la comprensión de procesos de negocio.
Optimizan la conservación y almacenamiento de los datos.
La distinción entre datos y metadatos no es siempre clara y depende del punto de vista del usuario. Por ejemplo, el título de un libro es parte del propio libro y, por tanto, es un dato, pero también sirve para catalogarlo y, por ello, puede ser un metadato.
Grandes volúmenes de datos (Big Data)
El Big Data es la gestión especializada de datos masivos, también conocida como ciencia de los datos.
El Big Data no solo se centra en el estudio de gran cantidad de datos, sino también en la gran variedad de los datos.
Para inferir conocimiento se utilizan herramientas estadísticas e informáticas para la agrupación y el análisis de los datos.
El Big Data va a encontrar patrones a través del análisis de comportamientos y afinidades de diferentes grupos de datos, permitiendo generar estrategias y acciones centradas en los mismos.
Información
La información puede entenderse como un conjunto de datos provisto de una relación semántica entre ellos, de tal forma que pasen a tener un significado. Es decir, los datos, por si solos, no tienen sentido.
Aunque pose un significado, no tiene porque ser útil.
Ejemplos:
El año de establecimiento de la empresa ACME fue 2010.
La altura del Empire State es de 443 metros.
DE es el código ISO que identifica el idioma Alemán.
Conocimiento
El conocimiento se construye a partir de la información y debe tener cierta utilidad o aportar algún tipo de valor.
Aunque el conocimiento se construye a partir de la información, más información no necesariamente generará más conocimiento.
El conocimiento se basa en la experiencia.
Los primeros sistemas basados en conocimiento se conocen como sistemas expertos.
Seguridad de los datos
La seguridad de los datos debe ser manejada de manera integral y completa durante todo el ciclo de vida del dato, abarcando los procesos de:
Captura del dato:
Planificación.
Desarrollo y ejecución.
Acceso al dato:
Autenticación.
Autorización.
Auditoria de seguridad de almacenamiento de datos.
Los procedimientos de seguridad de los datos deben ser dinámicos, adaptables y configurables en el tiempo.
La integridad de los datos está orientada al:
Mantenimiento: almacenamiento y actualizaciones.
Garantía de precisión: verificación, validación y aceptación
Coherencia: sin contradicciones en redundancia de datos.
Calidad de los datos
La calidad de los datos es el conjunto de propiedades inherentes a los datos a través de las cuales pueden ser valorados o juzgados, dado que datos de baja calidad representan una afectación grave en la calidad de la información para la toma de decisiones.
Se consideran datos de calidad aquellos que satisfacen los requerimientos previstos para su uso y que, además, presentan:
Consistencia: integridad de los datos.
Precisión: los datos representan fielmente la realidad.
Integridad: la información proporcionada por los datos es suficiente para realizar las tareas deseadas.
Relevancia: cuanto respaldan los datos el propósito por el que se obtuvieron.
Accesibilidad: disponibilidad de los datos.
Seguridad: autorizaciones de acceso y medidas para su control.
Información y conocimiento
Describíamos en apartados anteriores que, la información puede entenderse como un conjunto de datos provisto de una relación semántica entre ellos, de tal forma que pasen a tener un significado. Además, el conocimiento se construye a partir de la información y debe tener cierta utilidad o aportar algún tipo de valor.
Interpretando esa información, obtenemos nueva información, que es lo que conocemos como conocimiento. El conocimieto se construye a partir de información, tiene una carga de subjetividad, es una capacidad humana y está basado en la experiencia. |
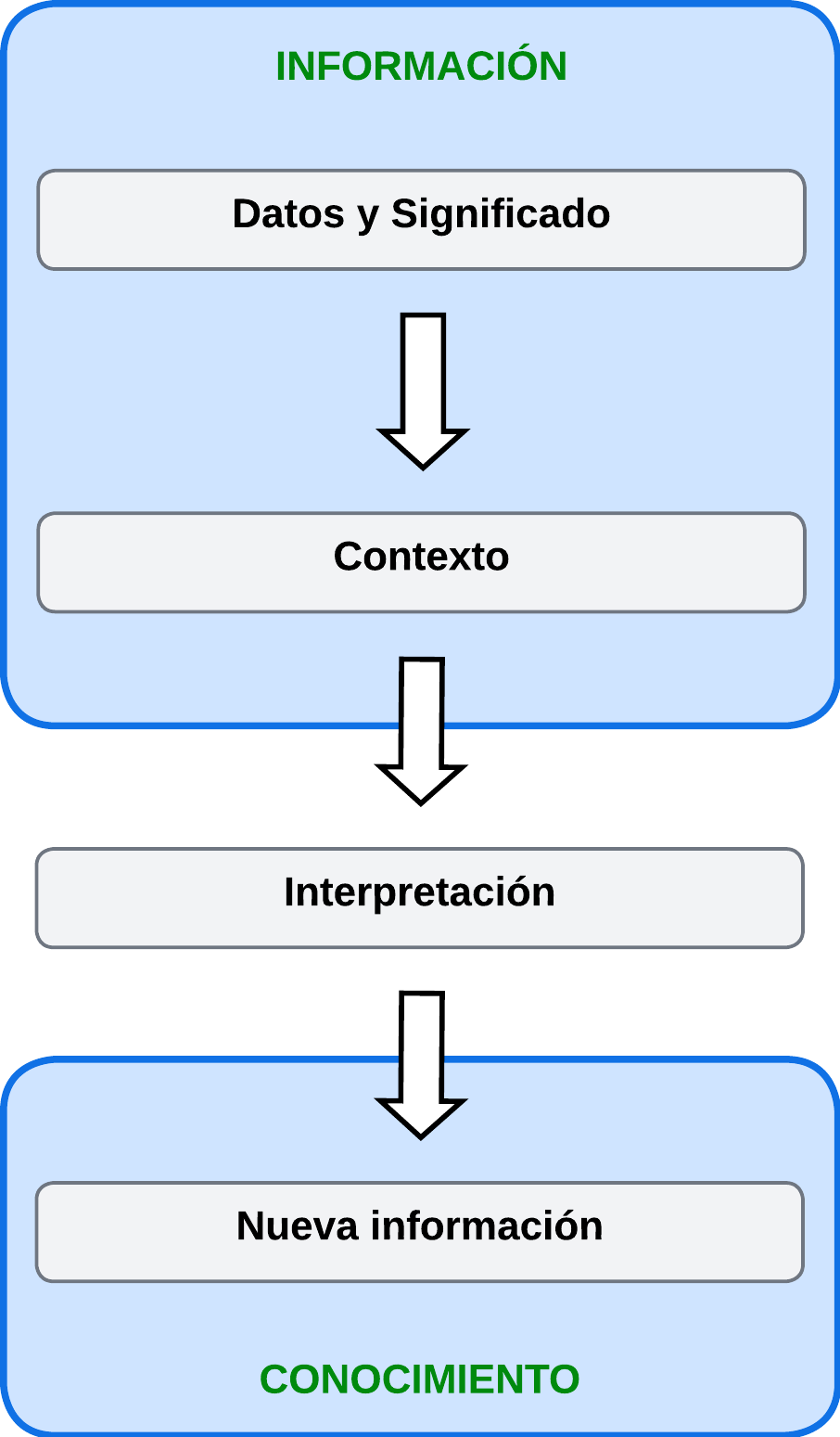 |
Desde un punto de vista filosofal, para que la información se transforme en conocimiento es necesario que ésta sea asimilada por un sujeto.
Sujeto que conoce.
Un objeto conocido.
La acción de conocer.
El resultado obtenido acerca del objeto.
Conocer es una combinación de experiencias (base de conocimiento), información contextual y relevancia de la información (calidad).
La comparación de información existente con la nueva información obtenida nos permite inferir modelos de comportamiento.
La generación de conocimiento surge a partir de REGLAS DE INFERENCIA.
De la mano de los expertos del dominio, y mediante técnicas lógicas, proporcionar unas reglas de inferencia (ontologías) que permitan cuantificar existencialmente la notación del conocimiento.
Su representación en sistemas computacionales se puede realizar a través de: Tripletas de objeto-atributo-valor, hechos inciertos, hechos difusos, mapas conceptuales, marcos, reglas, y ontologías